分布式MapReduce系统实现
MapReduce介绍
MapReduce 是一种由 Google 提出并实现的编程模型,主要用于处理和生成大规模数据集。它的设计思想借鉴了函数式编程中的两个基本操作:Map(映射) 和 Reduce(归约)。这个模型可以在分布式系统上高效地运行,支持海量数据的并行计算。
Map阶段
- 输入数据被分割成多个小块,由多个节点并行处理。
- 每个节点执行用户定义的 map 函数,生成一组中间键值对(key-value)。
Reduce阶段
- 中间结果按键分组,相同键的数据发送到同一个 Reduce 节点。
- 用户定义的 reduce 函数对值进行合并或计算(如求和、平均值等)。
执行概述
Map 调用通过自动将输入数据划分为 M 个分片,分布在多台机器上执行。这些输入分片可由不同机器并行处理。Reduce 调用则通过使用分区函数(例如,hash (key) mod R)将中间键空间划分为 R 个部分来进行分布。分区数(R)和分区函数由用户指定。
如图,当用户程序调用 MapReduce 函数时,会按以下顺序执行一系列操作: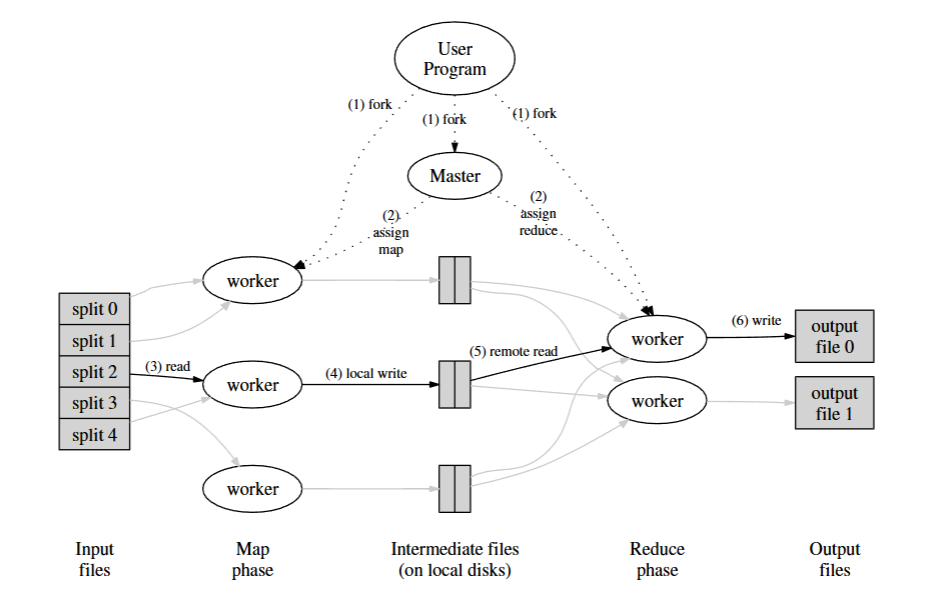
- 首先将输入文件分割成 M 个部分,然后在集群中的多台机器上启动该程序的多个副本。
- 其中一个程序副本是特殊的 —— 主节点(master)。其余副本为工作节点(worker),由主节点分配工作。有 M 个 Map 任务和 R 个 Reduce 任务需要分配。主节点选择空闲的工作节点,并为每个工作节点分配一个 Map 任务或 Reduce 任务。
- 被分配了 Map 任务的工作节点读取相应输入分片的内容。它从输入数据中解析出键值对,并将每个键值对传递给用户定义的 Map 函数。Map 函数生成的中间键值对会缓存在内存中。
- 每隔一段时间,缓存中的键值对会被写入本地磁盘,并通过分区函数划分为 R 个区域。这些缓存在本地磁盘上的键值对的位置信息会被传回给主节点,主节点负责将这些位置信息转发给 Reduce 工作节点。
- 当 Reduce 工作节点收到主节点关于这些位置的通知时,它会使用远程过程调用从 Map 工作节点的本地磁盘读取缓存数据。当 Reduce 工作节点读取完所有中间数据后,会根据中间键对数据进行排序,以便将相同键的所有数据聚集在一起。排序是必要的,因为通常许多不同的键会映射到同一个 Reduce 任务。如果中间数据量太大,无法全部放入内存,则会使用外部排序。
- Reduce 工作节点遍历排序后的中间数据,对于遇到的每个唯一的中间键,它会将该键和相应的中间值集合传递给用户的 Reduce 函数。Reduce 函数的输出会追加到该 Reduce 分区的最终输出文件中。
- 当所有 Map 任务和 Reduce 任务都完成后,主节点唤醒用户程序。此时,用户程序中的 MapReduce 调用返回到用户代码。
成功完成后,MapReduce 执行的输出会保存在 R 个输出文件中(每个 Reduce 任务对应一个文件,文件名由用户指定)。通常,用户不需要将这 R 个输出文件合并为一个文件 —— 他们经常将这些文件作为另一个 MapReduce 调用的输入,或者在其他能够处理多个分区输入文件的分布式应用程序中使用它们。
主节点( Master )数据结构
主节点维护着几个数据结构。对于每个 Map 任务和 Reduce 任务,它存储任务的状态(空闲、正在进行或已完成),以及工作机器的标识(对于非空闲任务)。
主节点是中间文件区域位置信息从 Map 任务传递到 Reduce 任务的通道。因此,对于每个已完成的 Map 任务,主节点会存储该 Map 任务生成的 R 个中间文件区域的位置和大小。随着 Map 任务的完成,会收到这些位置和大小信息的更新。这些信息会逐步推送给正在进行 Reduce 任务的工作节点。
实现
包括两个程序:coordinator(协调者) 和 worker(工作者)。整个系统只有一个协调者进程,但会有一个或多个并行运行的工作者进程。
在真实系统中,这些 worker 会运行在不同的机器上,但在这个实验中,它们都运行在同一台机器上。worker 会通过 RPC(远程过程调用) 与 coordinator 进行通信。
工作流程
每个worker进程会在一个循环中:
- 向coordinator请求一个任务;
- 读取任务输入(可能是一个或多个文件);
- 执行任务;
- 将任务输出写入一个或多个文件;
- 再次向coordinator请求新任务。
错误恢复
coordinator 应当能够检测到某个任务长时间未完成(在本实验中设定为10 秒),并将该任务重新分配给其他 worker。
Coordinator数据结构
根据论文中的内容,主节点(coordinator)需要存储 :
- Map任务列表以及 Reduce任务列表
- Reduce任务数量(nReduce)
- 当前整个工作的阶段(JobPhase)
- 互斥锁Mutex
每个任务需要存储:
- 任务ID
- 任务类型
- 任务状态
- Reduce任务数量,用于分区函数将Map节点的输出划分并映射至Reduce节点
- 开始时间,用于超时判断
- 输入文件列表,Map任务需要,Reduce任务可以不需要
1 | type Coordinator struct { |
RPC请求/响应结构体
coordinator(服务端)与 worker(客户端)通过 RPC 机制进行通信,请求和响应的结构体定义如下:
1 | type AssignTaskArgs struct {} |
Coordinator方法
Coordinator需要注册两个方法:AssignTask(用于coordinator向worker分配任务)和 ReportTask(用于worker向coordinator报告任务完成)
1 | func (c *Coordinator) AssignTask(args *AssignTaskArgs, reply *AssignTaskReply) error { |
辅助函数实现:
1 | func (c *Coordinator) initReduceTasks() { |
Worker方法
worker进程创建后,不断执行以下循环:
- 通过RPC向coordinator请求任务;
- 执行相应的Map或Reduce操作;
- 把输出文件保存为中间文件(Map)或最终输出(Reduce);
- 通过RPC通知coordinator自己完成了任务;
- 如果收到Wait/Exit指令,执行相应操作。
worker主循环实现如下:
1 | func Worker(mapf func(string, string) []KeyValue, |
辅助函数实现:
1 | func doMapTask(task TaskMeta, mapf func(string, string) []KeyValue) { |
运行
在一个终端中运行coordinator
1 | $ cd ~/6.5840 |
在另一个或多个终端中运行worker
1 | $ go run mrworker.go wc.so |
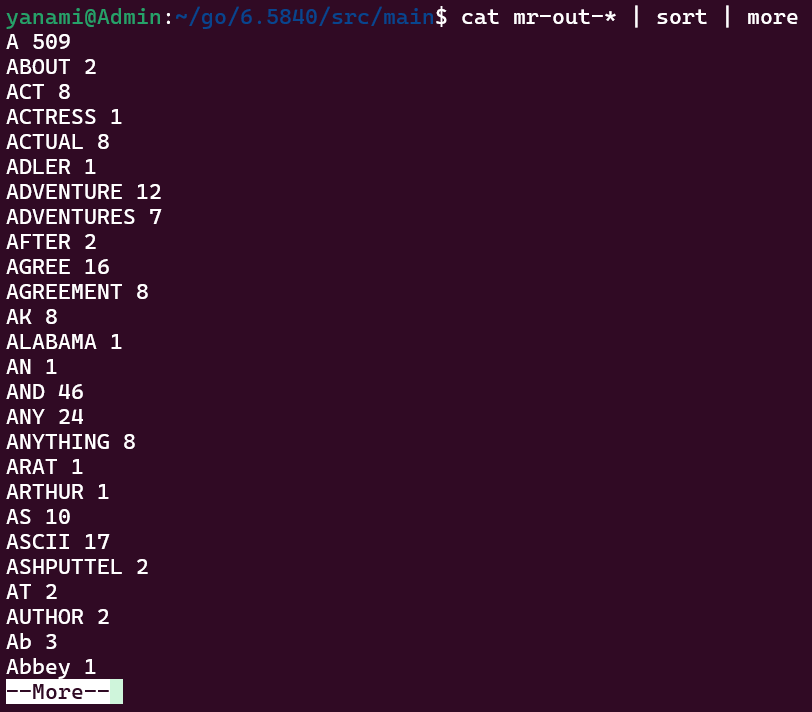
coordinator和所有worker运行结束后,输出结果保存在 mr-out-* 文件中,查看结果如下:
1 | $ cat mr-out-* | sort | more |
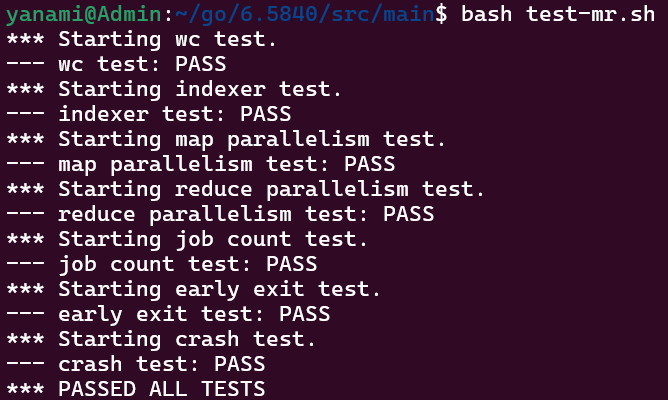
运行测试,结果如下:
1 | $ bash test-mr.sh |